Note
Click here to download the full example code
Pandas efficiency¶
Comparing the time complexities of different ways of building up a DataFrame from pieces.
import pandas as pd
import numpy as np
from scipy.stats.mstats import theilslopes
import matplotlib.pyplot as plt
import perfplot
from _benchmarking import plot_results, print_environment
empty_df = pd.DataFrame({i: [0]*10 for i in range(20)})
def pandas_concat(N):
df = empty_df
for i in range(1, N):
df = pd.concat([df, empty_df])
return df
def pandas_append(N):
df = empty_df
for i in range(1, N):
df = df.append(empty_df)
return df
def list_append(N):
lis = []
for i in range(N):
lis.append(empty_df)
df = pd.concat(lis)
return df
results = perfplot.bench(
setup=lambda n: n, # no setup needed for this exercise
kernels=[
pandas_concat,
pandas_append,
list_append,
],
labels=["pd.concat", "df.append", "list.append+pd.concat"],
n_range=np.logspace(0.5, 4.5, num=12).astype(int),
show_progress=False,
)
plt.style.use('default') # reset style changes made by perfplot
plot_results(results).show()
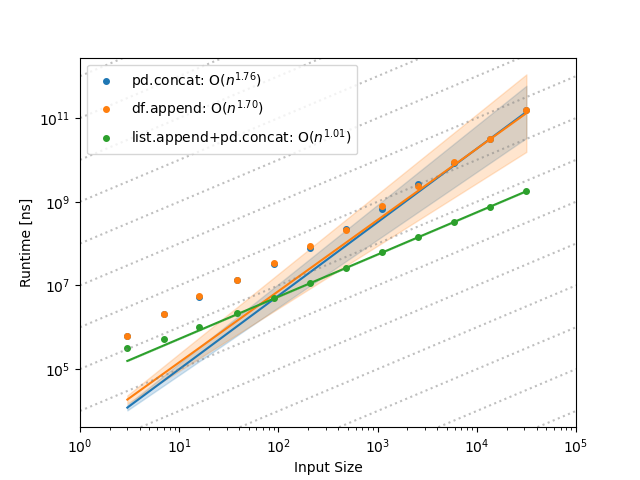
These results were generated in this environment:
print_environment()
Out:
3.7.9 (default, Aug 31 2020, 12:42:55)
[GCC 7.3.0]
pandas 1.2.2
numpy 1.19.2
matplotlib 3.3.4
scipy 1.6.0
pvlib 0.8.1
import subprocess
print((subprocess.check_output("lscpu", shell=True).strip()).decode())
Out:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 36 bits physical, 48 bits virtual
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 58
Model name: Intel(R) Core(TM) i5-3320M CPU @ 2.60GHz
Stepping: 9
CPU MHz: 1259.057
CPU max MHz: 3300.0000
CPU min MHz: 1200.0000
BogoMIPS: 5188.39
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 3072K
NUMA node0 CPU(s): 0-3
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm cpuid_fault epb pti tpr_shadow vnmi flexpriority ept vpid fsgsbase smep erms xsaveopt dtherm ida arat pln pts
Total running time of the script: ( 14 minutes 17.239 seconds)